Retrospectives @NeurIPS 2019
A Retrospective for "An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution"
- Original Paper : An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution
- Paper written by : Rosanne Liu, Joel Lehman, Piero Molino, Felipe Petroski Such, Eric Frank, Alex Sergeev, and Jason Yosinski
- Retrospective written by : Rosanne Liu, Joel Lehman, and Jason Yosinksi
Paper TL;DR
The main contribution of the paper was showing that a seemingly simple geometrical transformation was difficult for convolutional neural networks. A second contribution is a proposed fix, called CoordConv, which adds i,j pixel coordinates as additional inputs for a standard convolutional layer. Replacing standard convolution layers with CoordConv layers in several tasks (such as object detection, RL and generative models) improves performance.
An Experiment in Interviews for Retrospectives
One issue for retrospectives is the time and effort required to write them. Researchers are busy, and their incentives are oriented more towards writing new articles than reflecting on past ones. However, it can be fun to reminisce about old work, especially if someone is willing to indulgently listen. The authors of this retrospective (Rosanne, Joel, and Jason), at Jason’s suggestion, recorded a half-hour chat talking about a previous paper they collaborated on, and then transcribed and edited the interview for clarity and cohesiveness, which is shown below. We believe that interviews can potentially provide a relatively low-effort (especially if the product was audio without a polished transcript), and potentially fun way, to execute on retrospectives.
Overall Outlook
It started with a failure
Joel: Rosanne, how did this get started – what was the project that led to CoordConv?
Rosanne: It was something entirely different. Back then I was working on a project on emergent communication with Peter Dayan, and we wanted to study how agents establish communication schemes—with GANs!
Jason: I remember telling you it was a bad idea because GANs don’t work.
[Laughter]
Rosanne: Long story short, the premise of that project was to get GANs to reliably produce objects with different shapes and colors, and have them move around – appear at random locations. If you know about the CLEVR dataset, we basically want GANs to generate that, without a rendering engine or anything.
Jason: So your project started, and you said “let’s just figure out how to train GANs on moving objects with colors and shapes.”
Rosanne: Yes. “How to make GANs work?” We’ve seen successful examples of GANs, but when you start working with them – especially on generating isolated objects moving about – it is very hard. You start to form this confusion between, am I not good enough at this, or are the GANs not good enough? This constant debate haunted me: is it my failure or is it the GAN’s failure?
Jason: That was the point of the paper in the end, basically to prove that you weren’t a failure. I can’t believe it took us seven people and six months just to prop up your delicate ego.
[Laughter]
Jason: So you spent six months training GANs to draw squares, and the squares they drew weren’t quite squares.
Rosanne: Well, actually, we started out more ambitious, aiming at the CLEVR dataset, with realistic 3D objects. That was hard, so we reduced it to sort-of-CLEVR, where objects are 2D. But there were still too many shapes and colors for GANs to work, so we further reduced it to two shapes and two colors, then one shape (squares) and black and white.
Jason: So that was maybe three or five months in, and you were generating shapes and they were okay.
Rosanne: Yes, but not in a way that was good enough for the project. GANs made decent shapes, maybe 1 out of 10 tries, but there were issues like mode collapse, and other things we were trying to fix.
Jason: Right – things were oscillating. The discriminator was always winning and then always losing, always winning – back and forth and not converging. And you had no metric to judge quality – I think Peter was frustrated with that. Looking at the discriminator loss and generator loss, you can’t really tell whether the samples are good. It wasn’t clear what numbers you should be watching.
Rosanne: Yeah – a lot of confusing things going on, and everyone’s frustrated, everyone’s sad.
Debugging the Failure
Joel: So how did we get from there to CoordConv?
Rosanne: Well then we started to think: why can’t GANs generate a good distribution of simple shapes – why can’t that simple concept work? We thought of all kinds of assumptions of where the model might break. We know having GANs draw shapes is easy – it paints faces, after all. So maybe it is the discreteness. Maybe at some point the network has to have discrete signals of where to draw the shapes and what shapes to draw. Since activations are continuous numbers throughout the layers of a neural network generator, maybe what we need is an architecture that takes the GAN’s noise vector and reduce it to a point where we sample discrete signals, and then generate image from those samples.
Joel: That was on one of the whiteboard brainstorming images?
Jason: Enter exhibit one.
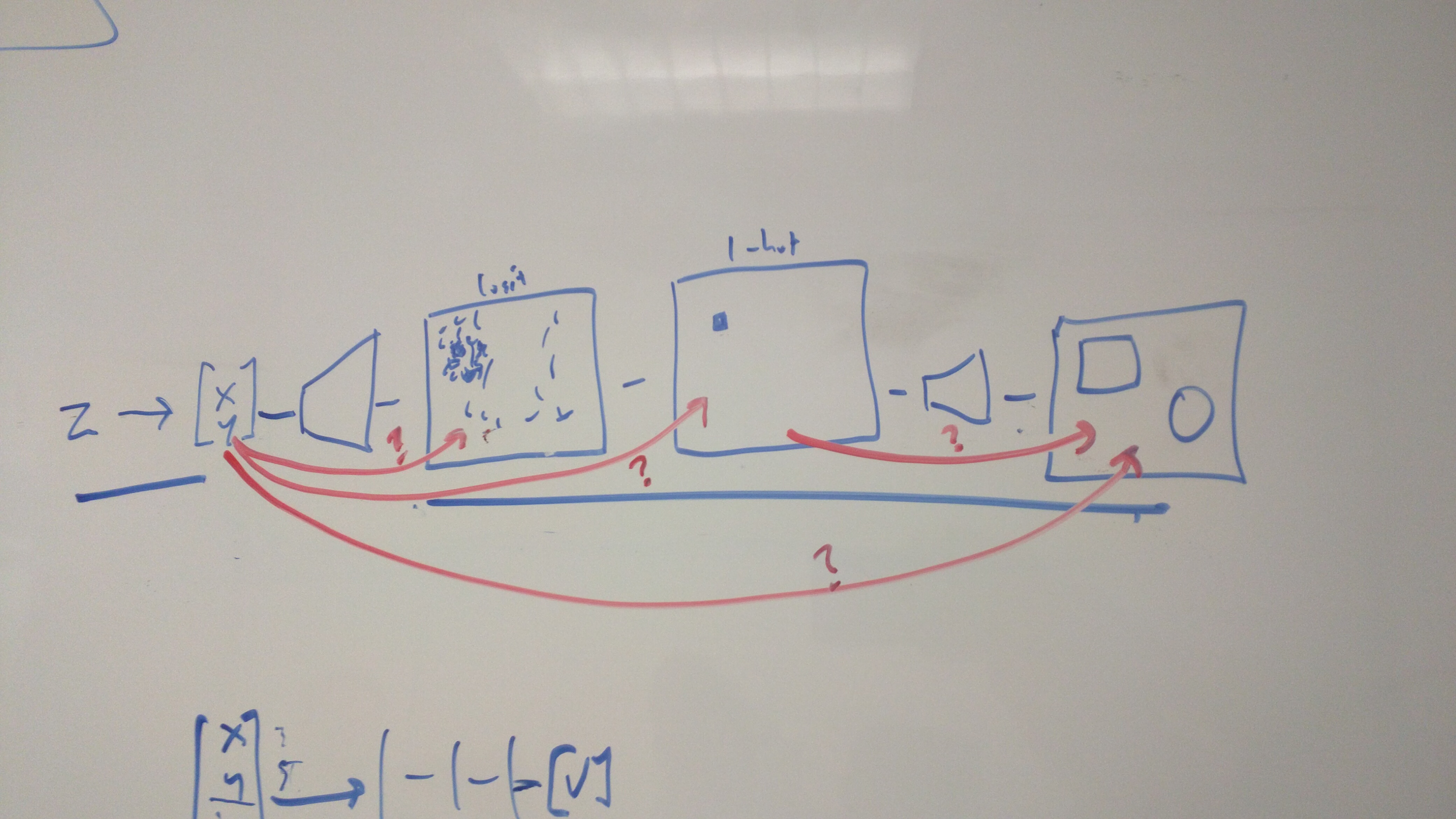 *Photo of a white-board drawing during the CoordConv project, representing a possible pipeline for how painting shapes in particular coordinates could work in a neural network, suggesting a suite of experiments to narrow down what the challenging and easy parts of the learning problem were. *
*Photo of a white-board drawing during the CoordConv project, representing a possible pipeline for how painting shapes in particular coordinates could work in a neural network, suggesting a suite of experiments to narrow down what the challenging and easy parts of the learning problem were. *
Jason: The whole pipeline is we need moving shapes generated from z (noise). It could involve a couple of steps. First from z (noise) to X and Y coordinates – that should be easy; any two dimensions in z could simply encode coordinate information. But can you from there produce reasonable logits for a single shape? And given reasonable logits can you produce a sharp 1-hot version, without softmax, just using convolutional layers? If you are painting two types of objects, I think we were gonna help the model by having two separate one-hots, one for the square, one for the circle. Assuming you had separate one hots, could you from there paint a circle and square?
Jason: And then even if everything worked when supervised piecewise, could you go from X, Y all the way to painted shapes? Maybe every stage is trainable separately, but the whole thing end to end doesn’t work. So we started to prove whether this whole pipeline would or would not work, trained separately or together, with supervision or without. Then, this huge table was laid out; this is now early May, and T minus three weeks to NeurIPS, right?
 Photo of a white-board diagram during the CoordConv project, suggesting a concrete set of experiments to explore what makes the painting problem difficult for deconvolutional networks, along with a nascent idea of what might provide a potential fix (CPPN).
Photo of a white-board diagram during the CoordConv project, suggesting a concrete set of experiments to explore what makes the painting problem difficult for deconvolutional networks, along with a nascent idea of what might provide a potential fix (CPPN).
Jason: We had all these experiments – with soft max, without soft max, with deconv versus an improved network, looking at the different stages of a pixel-painting pipeline, with supervision, without supervision. There was a whole table of experiments to be run.
Rosanne: And, I finished it.
Jason: The whole table?
Rosanne: Yeah! But we didn’t end up putting it in the paper. We reduced the story – a lot of it was just proving the concept. Those parts we thought should be easy, they were indeed easy. Not really surprising or interesting to show it in the paper.
Jason: Right, right – given an input pixel, painting a square centered around it is easy, and nobody cares.
Jason: We had this whole plan, from that picture. Which piece of the pipeline’s broken? That was a major step of the project. Something in this pipeline is broken. We just need to figure out which piece.
Rosanne: Yes! Again the central question was whether I’m the failure or the model is the failure. The philosophical question of, is the world wrong, or am I wrong?
Joel: So there’s the problem – but how did we arrive at the solution, what would become CoordConv? There was some kind of vague CPPN inspiration, right?
Jason: I think Joel’s idea was like we should just try putting a CPPN in this whole thing. And that was our goal, that was the thing we were going to try. I forget if we actually even tried that. I don’t know – or if we just realized, like why don’t we start with something simpler, which is just feeding in the coordinates.
Rosanne: And I think we’ve got to CoordConv from CPPNs because I asked Joel how to implement a CPPN, and he said the easiest way is just to populate the coordinates as inputs to a 1x1 convolution – which got us thinking that well, we could just put coordinates as inputs into any convolution.
The First Working Results
Jason: So which result that made into the CoordConv paper did we get first? Was it single-pixel painting?
Rosanne: The pixel painting and square painting were done at the same time. They’re very similar.We never had to tweak either one to make them work with CoordConv. That was working right away.
Jason: And it was kind of shortly after that, or a bit in parallel, we tried the other direction too.
Joel: Yeah, the coordinate regression. I think in all honesty, I think I had too much on my plate at the time, because I know I was really trying to get the models to work and I don’t remember the exact sequence of things, but, suddenly it started working with CoordConv. I could never get it to work without CoordConv, but I didn’t understand exactly what change helped CoordConv to begin to work. Once it started working I thought, well, I’m not going to mess with that any more, it works, that’s great. Then later it turned out that there was not a ReLU on the last layer, is that right?
Rosanne: There’s not a ReLU on any layer – but max pooling at the end.
Jason: So the version that first worked had no ReLUs? That’s interesting, it seems like we should’ve put that in the paper.
Joel: Well, we didn’t know until afterwards – it’s in the code, but not in the paper. And then it turns out it’s sensitive to those ReLUs in some ways which aren’t quite obvious. I did some fiddling reimplementing it, and the model turned out to be more finicky than I’d like, although it works, and without CoordConv I could never get it to perform well.
Jason: Cool – well that’s a perfect thing to include in the retrospective.
Jason: So we had the pixel painting and the square painting, and then shortly after we had the inverse – the coordinate regression. At that point, which is about a few weeks before the paper deadline, we thought okay, this is the story. Something’s hard that you wouldn’t think was hard. This is why it’s hard – here’s a clear demonstration of it being hard, and you can make it easy by adding coordinates. Having the story is what gave us the ability to recruit other colleagues. Our team was the three of us plus Eric, and then we added three more people.
Rosanne: Yes, that’s a good retrospective. That kind of team-building success I was not able to replicate consistently later on. I have since worked on projects with large and small teams, but it had never worked as nicely. With this one we got a team assembled in such a short time, because the solution was a simple function that you can easily wrap into a layer. Everyone plugged it into their framework and just tried it out, and it would work or not work, with really fast turn-around, as opposed to other projects when you try to incorporate more people towards the end, you give them this giant codebase that’s hard for them to catch up and figure out.
Jason: Then what happened?
Rosanne: We all just quickly tried things in parallel. We weren’t necessarily expecting anything – if there’s interesting results, we’d include them – but then they all turned out to be working.
Jason: All right, so then we submitted to NeurIPS. It was a rush at the last minute, but we got it out there.
Making the Companion Video
Joel: So when did the video happen – was that after we knew it was accepted?
Rosanne: That was in July – no, we didn’t know the acceptance yet. We tried to get the video out before ICML, that was our strategy. ICML happened before NeurIPS acceptance notices went out.
Jason: We spent a month, getting the clean version of the arXiv version out, which was much better than the NeurIPS submission, and writing the blog post. And the video took a whole weekend to make….which was…fun?
Joel: It was good, it was intense.
Rosanne: We should do it again sometime, when we have another paper with Joel, to feature his bad acting.
Joel: Corn Conv, Corn cob, whatever! It’s hard to pronounce.
[laughter]
Rosanne: Well the whole video to film didn’t take much more than a weekend.
Jason: It was about two or three days of making the script, which we also finished during the weekend. And then a solid weekend filming, and then editing afterwards, it does take a long time. Maybe there are better tools than iMovie, or better people than me, but it’s not fast at all.
Rosanne: Is that a retrospective part – that we could have hired professionals to help make it? But it seems cute, how it was made by non-professionals, and it’s more to our taste.
Rosanne: In general, I think the video is a very good idea, it was Jason and I’s second time doing it together, and Jason has done more before – I think people know us more because of it.
Jason: I think the idea is that if you have N minutes of someone’s time, pack as much information, actual knowledge transfer in there as you can, while making it fun enough that they don’t close the video. I think that’s what we aimed at, and we did a decent job at that.
Rosanne: You’ve always had a style of communicating to people about your ideas, in a simple way. You write “casual abstracts,” for your papers, before the whole video shooting idea. The video idea was quite a success, but what I’m saying is it’s not an accident. It naturally came about with our way of doing things.
Jason: I didn’t use to write those casual abstracts. Then for one paper, I posted on Facebook, we have this paper, and then added a comment, here’s a short casual description of what we’re doing in plain English. Then the next paper I posted, someone’s first comment was “Where’s the casual abstract, capital C, capital A, parentheses, T.M.?” So now I capitalize it.
Jason: One thing I realized once ICLR started and they were using open interview, was that since the reviews are public, you get to see reviewers answer the question for every paper “summarize the paper simply.” What I realized is that reading someone’s summary of the paper is so much better than reading either the abstract or the paper. Why is it so much better than the paper’s abstract – because it’s like debiased and de-hyped. It’s just, here’s what they actually did. It’s so useful. You feel like you understand almost the whole paper, by reading an honest description of it.
Joel: It’s without all the framing and strategy, to maximize chances at acceptance or impact.
Jason: Yeah, without overstating or claiming over-generalization of this big idea, which you didn’t really execute on.
Rosanne: Without all that (the framing and strategy angles), it’s just a language switch – from formal to casual, which papers somehow still don’t allow.
What You Would Do Differently
Joel: One prompt for retrospectives is, if you were telling a friend about this paper, how would you tell it differently to them than how it is in the paper?
Rosanne: I would tell the story backwards, almost – in the paper it’s “we found this failure, we’re digging into this failure, and then we’re half-way in the paper, and then only one-fifth of the paper is about how good the fix is and how it works” – if I were to tell someone in person I might just say, I have a fix for Conv, works well almost everywhere, if you want to know more about how we discovered it, I can tell you.
Joel: Yeah, it’s just a couple of lines of code, and if there’s some intuition you have that your problem or model could use a geometric bias, why not give it a shot?
Jason: I think my elevator version is, you would think it’s easy to make convolution paint some pictures, for pictures, for example, a single pixel – you tell it what pixel. Our paper shows it’s actually really hard.
Jason: I think one thing, it’s not a difference in how the paper presented it and I would present it now, but it’s the difference between how the paper was received and how I wish it was received. People have a strong bias thinking that all papers have to be about how we invented something new that’s better, rather than here’s a distillation of knowledge that you should probably have. I think our paper’s most important part is the discovery of this problem, the rigorous measuring and explanation for what’s going on. And then the fix is almost irrelevant, there are other possible fixes. Although, we did make the name of the paper contain CoordConv. There were so many people that read it, reviewers and others, saying “People have tried this before, this isn’t that new.” But we weren’t trying to say that – that’s not the interesting part. That’s a gap between what we intended and the way it was received – so what could we do differently next time to decrease that gap? We could’ve not named the fix. We could’ve maybe given a stronger name to the problem itself. We did call it the coordinate transform problem, but it wasn’t in the title.
Jason: Also, we definitely could have cited more papers in the initial version. We only found out about all the other similar methods after we put the work out there. People yelled at us, then we added a lot of cites. I wish we could have narrowed that gap.
Rosanne: Somehow I think naming was a good idea, it was a good idea for selling the paper. I mean, selling and branding is part of what we do, it’s important.
Jason: True – even with the angry people, I don’t think we should regret the name, because it really worked. Another question is, do you regret not releasing the code earlier? Another happy accident!
Rosanne: Yeah – a happy accident! Now, I regret it less. I used to regret it more. I released the code almost 7 months later than I should, and during that time there were numerous implementations that people did for me. Happy accident, because I indirectly encouraged the community to do this thing that I didn’t do.
Rosanne: Also – the first release of the paper, the sample code we provided in the appendix (it’s simple enough to be in a few lines), had a little bug. Someone found that, and they released their version of the code – they said, CoordConv with bug fixed, and people would star that implementation.
Jason: The version you eventually released, you fixed that bug?
Rosanne: Yeah, of course – it was just a bug that if you used a different height and width then it would break, but we used square images in all our experiments, so it didn’t come up for us.
New Perspectives
Jason: One question is, how do you see the paper differently now than back then – new perspectives on your own work?
Joel: I don’t know that I see the work itself in a different light, but the process by which that work came to be is interesting to me, how research happens, how important it is to always be curious. If you find an unexpected problem, then drill into that problem. It’s inspiring, how Rosanne kept going and figured this out.
Rosanne: I feel there was a big chance the paper would go without the fix. We knew we would find the problem, but we didn’t know we would find the fix. Revealing a problem itself seems like a worthwhile scientific investigation, but it wouldn’t be as good of a paper to the community. Is having that kind of good paper related to having the luck to find something that also has a fix?
Jason: I think most times when you really understand a problem, a fix can often be obvious. I think the hard problem ends up being understanding the problem.
Joel: And how do you look at it differently now?
Jason: I’d say the science is just as it was, I don’t see it differently now. The process was interesting. The process worked because we were as fast as we were. If we took our process and slowed it down by a factor of two, by the deadline we would have had nothing at all, and we would have killed the project, because at that point it was just GANs that don’t work, right, which aren’t that interesting. The way the team came together, too, was important, so the fact that the four of us (with Eric) were pretty committed early on, and worked on it for quite a while, put in enough time to see it through. Then we added people on at the end to hammer the point home, we showed that it does generalize quite a bit.
Rosanne: I think that’s because we had experience working together – a year before we worked together on another project, code-named LUprop, which sadly didn’t make it to NeurIPS. But we had gone through the research process together, especially a multitude of difficulties together, and so we had the faith that this time we can make something, or even if not we’d have fun. Because like most research, there are lots of moments we could have given up, when things just were not working. So trust-worthy work companions makes a big difference.
Jason: You trust enough, you’re fast enough, you’re good enough, you like each other enough. That way, when you hit a bit of a wall, you can turn, and roll with that. There were several turns that could have killed the project without a team that was as well-equipped.